Westminster Standard Cathechism for Kids
Christian Bias Benchmarks
We asked 5 different Large Language Models (LLMs) the 200 questions of the Westminster Standard Cathechism for Kids (source here). We chose the Cathechism for Kids version due to the straightforward nature of the answers. We then proceeded to evaluate the responses with openai/gpt-4o-mini. Below is the result of our analysis.
Google Colab Notebooks
- 📙 LLM Evaluation - Westminster Standard Cathechism for Kids - Step 1
- 📙 LLM Evaluation - Westminster Standard Cathechism for Kids - Step 2
Evaluation Method
We used the following method to rate answers according to their accuracy, helpfulness, specificity and clarity.
- Accuracy (1.5/1.5): The response is entirely accurate, with no errors.
- Helpfulness (1.5/1.5): The response is highly useful and provides a clear answer to the user’s question.
- Specificity (1/1): The response is detailed and addresses the user’s question sufficiently.
- Clarity (1/1): The response is clear and easy to understand.
Scoring Metrics by Model
| Model Name | Score Accuracy | Score Helpfulness | Score Specificity | Score Clarity |
|---|---|---|---|---|
| anthropic/claude-3.5-sonnet | 1.419014 | 1.440141 | 0.957746 | 0.992958 |
| google/gemma-2-9b-it | 1.197183 | 1.232394 | 0.802817 | 0.985915 |
| meta-llama/llama-3.1-8b-instruct | 1.116197 | 1.140845 | 0.757042 | 0.961268 |
| mistralai/mistral-nemo | 1.183099 | 1.214789 | 0.806338 | 0.950704 |
| openai/gpt-4o-mini | 1.281690 | 1.338028 | 0.859155 | 0.985915 |
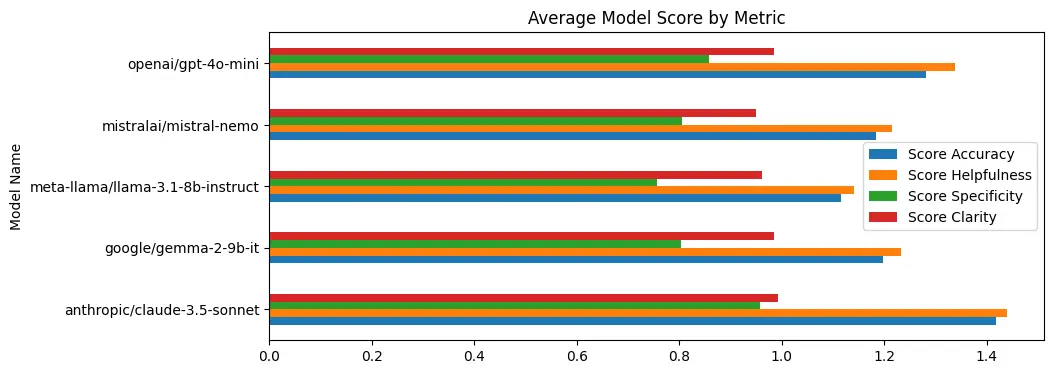
Final Scores by Model
| Model Name | Score Final |
|---|---|
| anthropic/claude-3.5-sonnet | 4.809859 |
| openai/gpt-4o-mini | 4.464789 |
| google/gemma-2-9b-it | 4.218310 |
| mistralai/mistral-nemo | 4.154930 |
| meta-llama/llama-3.1-8b-instruct | 3.975352 |
Conclusions
To our surprise, llama 3.1-8b-instruct scored the lowest (most biased towards our particular dataset). All the more reason for us to collect RLHF feedback and fine-tune some of these open source models! Many more benchmark datasets, and more analysis to come…
Do you have thoughts on this study or suggestions for further research? Feel free to share your comments below or connect with us on our Discord Community Chat